
I’d literally resigned from that company the week before LinkedIn recommended three positions to me.
I’d literally resigned from that company the week before LinkedIn recommended three positions to me.
When working with csv or strongly typed files from our dfs, I often want to grep a file but keep the first line of output which is a list of field names. grep, unfortunately, doesn’t seem to have any knowledge about line numbers. What I really want is something that essentially does:
1
| |
without having to type that over and over. You can kluge this together by putting a script named `grep“ in your personal bin:
1 2 3 4 5 6 | |
And if you create a testfile as so:
1 2 3 4 5 6 7 8 | |
Then
1 2 3 4 5 | |
and
1 2 3 4 5 | |
work as expected. It isn’t perfect. For example, if you include context around the matched lines — eg -C 3 — it’s possible to output the header twice, but it gets close to what I want without having to build a custom grep executable. Alternate suggestions seem to be to use sed or awk instead, but I prefer my solution since the regex syntax is slightly different for each program.

As generated by R’s boxplot function. I individually labeled the median, quartiles, min, max, and outliers for inclusion in a presentation where the audience can’t be assumed to know how to interpret box plots. Please feel free to use this image if you have a similar need.
In text, shamelessly stolen from the climate blog:
The rectangle shows the interquartile range (IQR); it goes from the first quartile (the 25th percentile) to the third quartile (the 75th percentile). The whiskers go from the minimum value to the maximum value unless the distance from the minimum value to the first quartile is more than 1.5 times the IQR. In that case the whisker extends out to the smallest value within 1.5 times the IQR from the first quartile. A similar rule is used for values larger than 1.5 times IQR from the third quartile. A special symbol shows the values, called outliers, which are smaller or larger than the whiskers
I may be the only person who feels this way, but it’s awfully easy to read a paper or a book, see some equations, think about them a bit, then sort of nod your head and think you understand them. However, when you go to actually implement them you look back and the jump from the symbols on the page to code that runs on a computer is little bigger than you thought. So this is mostly me thinking aloud, but I was reading about optimization functions that rely on the hessian and I wrote this out to make sure I understood this well enough to calculate it if I want.
I picked some random training data. First, we set up the design matrix x, the dependent variable y, and the theta (or beta) at which we will evaluate the hessian:
1 2 3 | |
Typically you’d put a column of ones on the left of the matrix as an intercept term, but I didn’t set my problem up that way. The Hessian is the n by n matrix of 2nd derivatives of a scalar valued function. In our case, there are two parameters, ie two explanatory variables, so
Note that we denote the ith of m training example as
the superscript in parentheses is not exponentiation. Here x is a column vector and y is either 0 or 1.
We also need some functions. R supports closures so you don’t have to pass x and y around.
1 2 3 4 5 | |
Finally, we can use the numDeriv package to calculate the Hessian and compare with a hand calculation:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
You can clearly see why any optimization algorithm requiring the hessian will be slow; you iterate over every training example once for each explanatory variable.
Also, MathJax is an awesome and painless latex for your blog.
As mentioned before, tee, a useful but horridly named utility, allows you to save stdout while echoing it to the screen. Sometimes, however, you need both stderr and stdout. Bash allows you to combine stderr and stdout by appending 2>&1 to your command. Thus
1
| |
saves both stderr and stdout, correctly temporally interleaved, to the specified log file.
For all of the web searchers, apparently Advantage can make cats have seizures.
Six months ago Lucy the cat got fleas, most likely from the vet where she’d been for some minor surgery. We applied canine advantage to our dog and feline advantage to the cat. Within minutes after applying the frontline to the cat, she had a small seizure. I’d had her 12 years at the time and, to the best of my knowledge, she’d never had a seizure before. We decided never to reapply Advantage to her.
This week, our dog got fleas. We applied canine advantage to the dog and nothing to the cat. She had a seizure a day later, her first seizure, to the best of our knowledge, since the last time we used advantage. Our vet thinks it may be because she likes to sleep in his upstairs kennel on his bed during the day because it gets a lot of sun.
These are the only two times I know of her having a seizure since I adopted her in October 1999. So if you find this via google, you’re not the only ones and I’d stay away from advantage, or at least closely monitor your cat if you use it. Our vet recommended Frontline for the next time either gets fleas; if we have to use it, I’ll post again.

Other accounts of cats having seizures after exposure to advantage are available here
I work with a bunch of data that often comes in text files. I regularly want to cut off the header / first line, but I thought that to use tail you had to know how many lines are in your file. It turns out that if you just use
$ tail -n +2 [file]
it will just skip the first line without forcing you to know how many lines there are.
earl $ cat a.csv
1
2
3
4
earl $ tail -n +2 a.csv
2
3
4
This is much more convenient for piping into awk or other commands downstream.
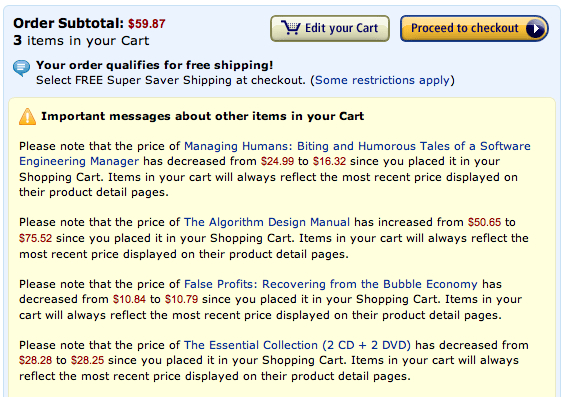
Does anyone else regularly see large price swings on Amazon? I’m in the habit of adding books to my shopping cart until I run out of things to read at home, then buying whatever is in my cart at the time. Thus I have books sitting in my cart for a month or so and every time you visit your cart amazon notifies you if prices have changed. Managing Humans dropped by $9 and The Algorithm Design Manual jumped by $25. The next two price changes are more characteristic, moving around by a couple cents.
When using bash, it’s really nice to both save the output of a command to a file and print it on the screen. I couldn’t find something that did this so I wrote my own ruby script. A utility that does exactly what you want is actually included in a standard linux install, but with a filename that I simply couldn’t google. tee does what you need:
1
| |
saves stdout to log.job.00 and echoes to screen
The biggest divide in the online advertising world is search advertising vs display advertising. Search sounds exactly like what it is: the ads next to search results on Google, Yahoo, Bing, and competitors. Search is bigger than display by revenues [1], and much more concentrated. The benefit of search to advertisers is it corresponds much better than display advertising to intent. A searcher for “hotels in Palm Springs” is most likely in the market for a hotel in Palm Springs. The other thing search has going for it is it’s easy and quantifiable — you can sign into google adwords with nothing more than your credit card, type up some text ads, and be running campaigns with impression and click reporting within hours.
The display advertising world is structured differently. Display ads are obviously those pictures you see plastered all over the sites you visit. There’s less intent so individual impressions earn a lot less money. Typically the prices are measured as cpm, cost per mille, ie cost per 1k impressions. It’s also important to understand the structure of the market a bit. In the beginning (90s), advertisers pretty naively bought ad impressions millions at a time on popular sites. Performance was often evaluated based on pure impressions or ctr, click through rates. Ads were often sold on the basis of quantifiability — you could, for the first time, measure how many ads were seen (in the sense that a user loaded the page), who clicked, how often, where he or she went, etc. As search advertising evolved, I think a lot of the people chasing quantifiable advertising moved to that, while display became more about branding. This, btw, is the value of facebook — brand advertisers want to be able to precisely target age, gender, income, and other demographics; on facebook, users freely and generally accurately share this information.
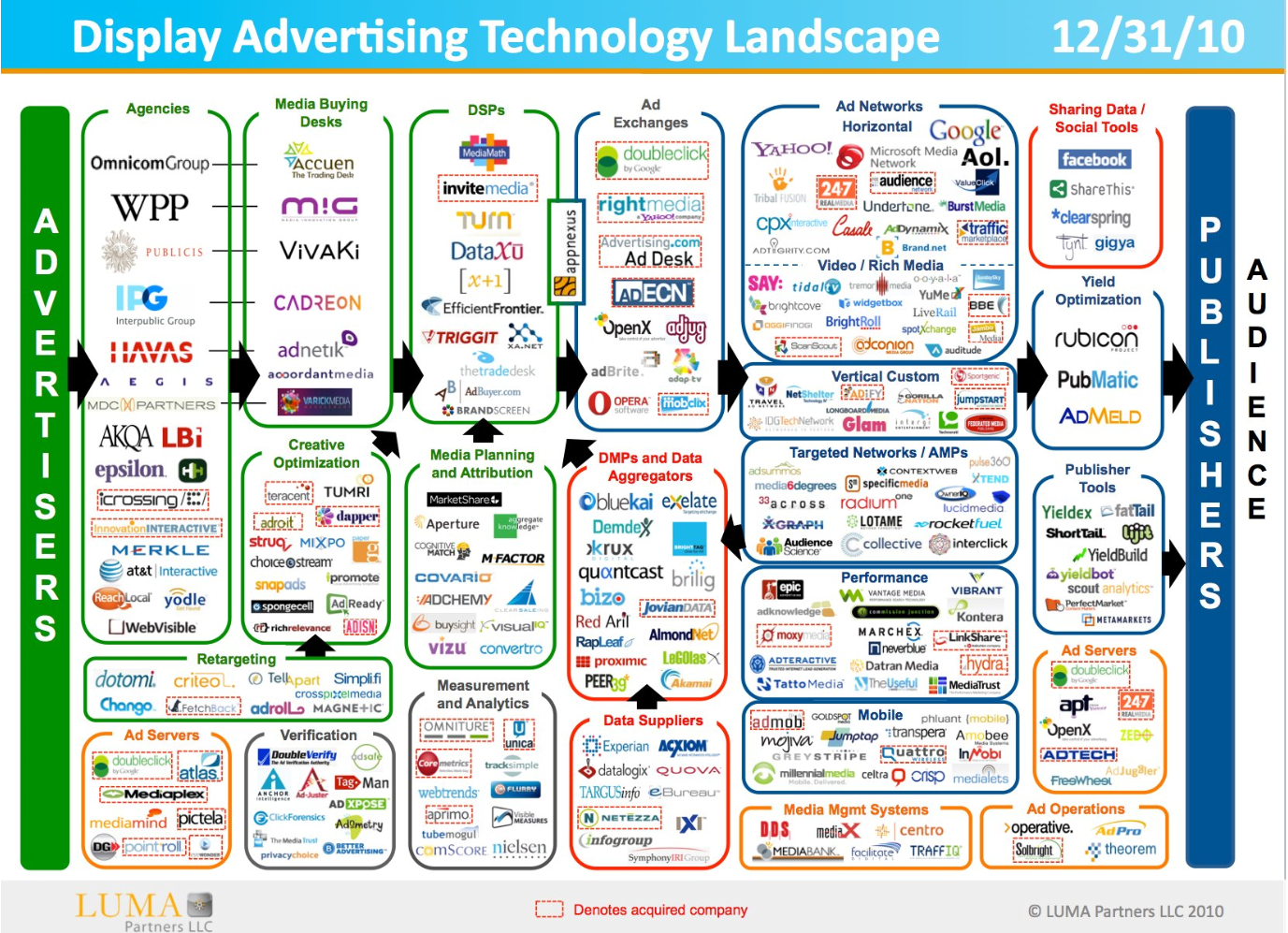
The display ecosystem has a bunch of moving pieces. If you look at the display advertising tech landscape graphic from Luma Partners, you’ll see:
Agencies — these are the (7?) big advertising agencies that run most large advertising accounts go through. Companies like Toyota, GM, General Mills, etc, will give these companies tens to hundreds of millions of dollars to run ad campaigns on their behalf.
Media Buying Desks — The ad agencies weren’t really capable of managing digital campaigns. That is, when ad agencies came about, your media outlets were maybe 10 national TV networks, radio stations, local newspapers, and a couple national magazines. And the media buying process was pretty simple: the agencies would send out an RFP that said we want manly men in their 40s who buy outdoorsy cologne and the aforementioned publishers would respond and say how their audience matched that profile. Compared to the online world of today, where there are thousands of premier publishers such as the NYT, ESPN, online magazine versions, etc; this was much simpler. Today, trafficking ads is an order of magnitude more work, and advertisers must decide what they want to buy, where, on which site, when, with what creatives, etc. So the agencies built or bought companies that have the capability to build digital media, traffic campaigns, optimize the ads, and create the necessary reporting. Eg Vivaki is Publicis, b3 is WPP, etc.
Ad Exchanges are, well, exchanges where publishers and advertisers come together to sell and buy remnant ad inventory. Basically, there is premier and remnant inventory. Premier inventory is something like display ads on high quality reporting on ESPN or ads on articles on ars technica. These are often sold by in house salespeople in a process remarkably similar to how everything used to work, though people mostly email pdfs instead of sending faxes. Every ad impression that isn’t sold as premier is referred to as remnant, and these remnant impressions are offered to ad exchanges such as Right Media — rmx, owned by Yahoo — in exchange for a cut. So the way this works is I can buy, with some rules, 1MM impressions on rmx and rmx will put these impressions on their publishers such as ESPN in ad impressions that ESPN didn’t sell in house. These impressions go for an order of magnitude less money than premier. RMX is one of the more technically sophisticated. The benefit for publishers is they get some money for inventory they didn’t fill. Just to be clear, a good ecpm for premier might be $20-$40 and a good ecpm for remnant might be $3-$5.
DSP ie Demand Site Platform — A DSP helps advertisers purchase remnant ads across multiple ad sources including exchanges, ad networks, and individual publishers. A good DSP will have sophisticated targeting and optimization algorithms that incorporate first and third party data on behalf of the advertisers. Typically, a DSP’s clients are advertisers that aren’t big enough to go to one of the big seven agencies. Often these advertisers spend $10 – $50k / month, for example a local Toyota dealership instead of the national dealer chain, etc.
Ad Servers — these help publishers. See eg OpenX, DoubleClick Dart, etc. Particularly for larger publishers, coordinating all these ad purchases is complicated. Your advertisers want to give you rules, such as user bleaching rules (only so many impressions to a given user per some amount of time), time of day, what pages an ad can run on (few people want to run next to naked folks, etc). They also want to be able to update and optimize their creatives or even change the creatives or the landing page they go to. Advertisers, or their agencies, also demand reporting — how many times was an ad seen. On what pages did users click on the ad. etc. Within publishers the ad sales or monetization folks don’t want to be releasing the site every time they tweak ads. Ad servers are internal or external software that manages all this and can be quite complex.
Data optimization — this requires some explanation. In the beginning, people basically bought broad swaths of display ads. The value to optimization is the more targeted you can make your ad, the more value it has. My favorite example is espn: assume 10% of their online audience is female. If you’re an advertiser that wants to sell female sports jerseys, your ctr amongst women is 5%, your conversion rate is 5%, and a conversion is worth $50, your value per 1k impressions is 1000 * .1 * .05 * .05 * 50 = $12.5, so your cpm has to be < $12.50. However, if espn could pick out the women and sell the publisher only that segment (with some error, obviously), but say espn can enrich the demos so that women are 50% of impressions in a segment. Suddenly advertising on espn is worth 5 times as much for the advertiser and hence espn can charge 5 times as much. This is the value of data optimization. It’s performed many ways, from things as simple as geo targeting and day parting to more sophisticated demographic estimation, retargeting, and varieties of behavioral retargeting.
Retargeters — Retargeting is a simple idea. Say that I see cookies going to a site like a bmw forum. I might reasonably intuit that these users are interested in bmws and choose to show bmw display ads to them as they browse the internet.
Behavioral retargeting is the next step of retargeting. Plain retargeting is nice, but it suffers from a couple flaws. First, it has limited reach, ie there are only so many cookies that go to a bmw forum. BMW probably wants to reach more purchasers than just those. Second, it doesn’t really help generate intent. If you’re going to a bmw forum, you’re probably already pretty interested in bmws, so that may not be the best person for bmw to advertise to. Behavioral retargeting means any of a variety of ways of trying to figure out cookies to advertise to to get broader reach or cheaper acquisitions than retargeting.
The other big movement going on in the display world is the evolution of how people buy ads. In the early days — 90s — people tended to buy online ads in a high touch process with salespeople. Ad networks started which brought more buyers and fewer salespeople. Companies like Right Media — which Yahoo bought — started and allowed you to create bidding rules that run on their servers so advertisers can buy ads. So I can say that I want to, across many websites, target cookies that have visited a site or set of sites (retargeting), or show them so many ads per day, etc, and based on a variety of characteristics of a cookie and the site which that cookie is visiting and the web page they are viewing, $X is my bid for that cookie. RTB or real time bidding is the new new — now, instead of giving limited rules to someone like RMX, you register with Google (the largest RTB platform) or Yahoo’s RTB, and their servers, for each impression, send you a bid request. Your computers located in a server farm near their servers are given typically 100ms to respond with a per impression bid for that cookie on that page and that impression. See [2]. Also, this is obviously an enormous tech investment. DSPs also help with this; most companies aren’t capable nor is it worthwhile to build this out in house.
NB: I work for one of these companies. My posts are not now, have never been, and probably never will be the official opinion of my employers nor endorsed by any of them. You should not infer anything about my employers from anything I write. Seriously. Don’t be a tool.
[1] Techcrunch: Online Advertising Revenues Up 23 Percent Since Q1 2010, Reach $7.3 Billion
[2] Business Insider: The Rise Of Real-Time Bidding Is The Biggest Online Advertising Story Of 2010
Updated: 2012 0526